 Blog Home
Blog Home
Converting CSV to parquet in Clojure
Parquet File Format
Developers of data-intensive applications are getting increasingly exited recently about the parquet file format. From the parquet home page:
Apache Parquet is an open source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk.
In practice, this means both smaller files (saving on storage costs), and much faster loading of data. This makes a lot of sense, in CSV data is stored as characters and needs to be parsed on each load, while in parquet data can be stored columnar with packed native binary representations.
A lot of the library code to enable working with parquet files is squirreled away inside of Hadoop and other places, and so reading and writing parquet files is more onerous than it should be. Here at TechAscent, we love Clojure because it takes the drudgery out of writing the kind of software we write, and we wanted to extend this to parquet.
To that end, we have produced a single .jar that makes working with parquet much easier from Clojure, and published it in obvious places.

Show me how!
Here are some short programs showing how easy it can be to convert CSV to parquet in Clojure with this library.
First, these are the requires:
(:require [tech.v3.dataset :as ds]
[tech.v3.io :as io]
[tech.v3.dataset.io.csv :as ds-csv]
[tech.v3.libs.parquet :as parquet])
Then, we can make a little CSV:
(defn make-little-csv!
[]
(-> (ds/->>dataset {:x (concat (repeat 3 "a") (repeat 3 "b"))
:y (range 6)
:z (repeatedly 6 rand)})
(ds/write! "little.csv")))
And one possible output of that looks like this:
$ cat little.csv
x,y,z
a,0,0.06599589537334993
a,1,0.626120442946226
a,2,0.9676410561136666
b,3,0.10221964740063405
b,4,0.7847202585478524
b,5,0.027999692367451368
Converting that file to parquet is a two-liner (!):
(-> (ds/->dataset "little.csv")
(parquet/ds->parquet "little.parquet"))
And visidata can load the resulting parquet file:
$ vd little.parquet
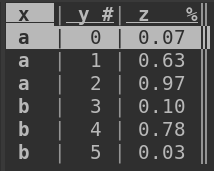
Note the # and %, which indicate that visidata recognized the y column as an integer and the z column as a floating point number. In CSV, of course, they're just strings.
Yes, but my CSV files have more than six rows
Here is another example of a bigger CSV with ten columns and one million rows:
(defn make-big-csv!
[]
(let [xs (for [i (range 8)] (str "x" i))
chosen-x (rand-nth xs)]
(-> (for [i (range 1000000)]
(let [o (reduce (fn [eax x] (assoc eax x (rand)))
{"id" i}
xs)]
(assoc o "y" (if (> (get o chosen-x) 0.5) "green" "magenta"))))
(ds/->dataset)
(ds/select-columns (concat ["id"] xs ["y"]))
(ds/write! "big.csv.gz"))))
And converting that to parquet is also easy:
(->> (io/gzip-input-stream "big.csv.gz")
(ds-csv/csv->dataset-seq)
(parquet/ds-seq->parquet "big.parquet"))
The intermediate step here streams the CSV into batches of configurable size (by default each batch is 128,000 rows), which implies two important things:
- the CSV doesn't need to be stored locally (e.g., it could be a stream from cloud storage)
- the whole CSV never needs to be in memory all at once – since it is processed in batches
Moreover, the resulting parquet file reads much, much faster:
> (time (ds/row-count (ds/->dataset "big.csv.gz")))
"Elapsed time: 5219.210522 msecs"
1000000
> (time (ds/row-count (ds/->dataset "big.parquet")))
"Elapsed time: 826.464188 msecs"
1000000
For absolute maximum performance, it probably makes sense to separate the reading, and writing into their own threads. This would also precipitate an opportunity to introduce some transformation into process which would be typical in this kind of work, especially at scale. Reach out to us if you have an interest in that thread (no pun intended) of development.
Conclusion
Reading and writing parquet files from Clojure used to be more dramatic.
Now, it's easier – and that's the way we like it.
TechAscent: Delightfully efficient full-stack software development.